Excelで日々大量のデータを扱う中で、文字列の抽出、結合、書式設定といったデータ整形作業に多くの時間を費やしている方も少なくないでしょう。特に、データが不規則な形式で提供される場合、複雑な数式を組んだり、手作業で修正したりと、その手間は計り知れません。Microsoft ExcelのPower Queryに搭載されている「例からの列」機能は、こうしたデータ整形の課題を根本から解決し、作業の自動化と信頼性の向上を実現する強力なツールとして注目されています。
従来のFlash Fill機能や、MID、LEFT、FINDといった関数を組み合わせた複雑な数式に頼っていたユーザーにとって、「例からの列」はまさにゲームチェンジャーとなり得ます。一度パターンを学習させれば、元データが更新されても自動的に整形が適用されるため、手作業によるミスを減らし、大幅な効率化が期待できます。
「例からの列」とは?従来のデータ整形との比較
Excelにおけるデータ整形は、長らく複雑な数式や手動操作に依存してきました。しかし、これらの方法にはそれぞれ限界がありました。
複雑な数式によるデータ抽出・整形
MID、LEFT、FIND、LENなどの関数を組み合わせることで、特定の文字列を抽出したり、データを整形したりすることは可能です。しかし、これらの数式は非常に記述が複雑になりがちで、特に文字列の長さや区切り文字の位置が変動するようなデータでは、数式の調整が困難を極めます。また、数式が長くなると、トラブルシューティングも一苦労です。少しでもデータ構造が変わると、数式全体を見直す必要があり、メンテナンスコストが高くなります。
Flash Fillの利便性と限界
Excel 2013で導入されたFlash Fillは、ユーザーが入力したパターンを自動的に認識し、残りの列に適用してくれる画期的な機能でした。これにより、複雑な数式を組む手間が大幅に削減され、多くのユーザーに歓迎されました。しかし、Flash Fillにはいくつかの重要な限界があります。
- **データとの非リンク性:** Flash Fillは一度実行すると、その結果は静的な値としてセルに貼り付けられます。元データが更新されても、Flash Fillの結果は自動的に更新されません。再度実行するか、手動で修正する必要があります。
- **パターンの誤認識:** 複雑なパターンや曖昧なデータに対しては、Flash Fillが意図しないパターンを認識してしまうことがあります。特に、データセットが大きい場合、すべての行をチェックするのは現実的ではありません。
- **再利用性の低さ:** Flash Fillは基本的に一回限りの操作であり、その「ロジック」を保存して再利用することはできません。異なるデータセットや、同じデータセットの更新時に、毎回手動で操作を繰り返す必要があります。
Power Query「例からの列」の優位性
Power Queryの「例からの列」は、Flash Fillの直感的な操作性と、数式の構造的な信頼性を兼ね備えたハイブリッドなツールです。ユーザーがいくつかの例を入力するだけで、Power Queryは背後でM言語というスクリプトを生成し、そのパターンを学習します。このM言語スクリプトは、データ変換の「レシピ」として保存されるため、以下のような大きなメリットがあります。
- **自動更新:** 元データが更新された場合でも、Power Queryのクエリを「更新」するだけで、すべての変換ステップが自動的に再実行され、最新のデータに整形が適用されます。これにより、手動での再作業が不要になります。
- **柔軟なパターン認識:** ユーザーが提供する複数の例から、より柔軟で堅牢なパターンを推論します。Flash Fillよりも複雑なデータ構造や例外的なケースにも対応しやすいのが特徴です。
- **再利用可能な変換:** 作成されたクエリは、Excelブック内に保存され、いつでも再利用できます。同じ種類のデータが定期的に発生する場合、一度設定すれば以降の作業は大幅に効率化されます。
- **トラブルシューティングの容易さ:** Power Queryエディターの「適用したステップ」ペインで、各変換ステップを視覚的に確認・編集できるため、問題が発生した場合でも原因を特定しやすくなっています。
Power Query「例からの列」の基本的な使い方
「例からの列」を効果的に活用するためには、いくつかの準備と手順が必要です。ここでは、その基本的なワークフローを解説します。
データ準備:Excelテーブルへの変換
Power Queryは、データがExcelテーブルとしてフォーマットされている場合に最も効果的に機能します。テーブルは単一のオブジェクトとして扱われ、行が追加されても自動的に範囲が拡張されるため、クエリの信頼性が高まります。
- 整形したいデータ範囲内の任意のセルを選択します。
Ctrl + Tを押すか、「挿入」タブの「テーブル」をクリックして、データをExcelテーブルに変換します。- テーブルに分かりやすい名前を付けておくと、後で参照しやすくなります(例:
T_MasterLogs)。
Power Queryエディターの起動
データがテーブルになったら、Power Queryエディターを起動します。
- テーブル内の任意のセルを選択します。
- 「データ」タブに移動し、「データの取得と変換」グループにある「テーブルまたは範囲から」をクリックします。
- 新しいウィンドウでPower Queryエディターが開きます。ここに元のテーブルが表示されます。
「例からの列」の選択と初期入力
Power Queryエディターで「例からの列」機能を使用します。
- Power Queryエディターの「列の追加」タブをクリックします。
- 「例からの列」グループにある「例からの列」をクリックします。ドロップダウンメニューが表示されたら、「すべての列から」または「選択範囲から」を選択します。
- 新しい空の列が追加されます。この列の最初の行に、目的の出力結果を手動で入力し、
Enterキーを押します。 - Power Queryは、入力された例に基づいてパターンを推論し、残りの行に候補を表示します。
「過学習」の重要性
Power Queryが提示する候補が正確に見えても、特にデータセットが大きい場合や、データに多様なパターンが含まれる可能性がある場合は、「過学習」を行うことを強く推奨します。これは、Power Queryの推論ロジックをより堅牢にするための重要なステップです。
- 候補が表示された後も、データセットをスクロールし、異なる構造を持つ行や、Power Queryが誤認識している可能性のある行を見つけます。
- そのような行の新しい列に、正しい出力結果を手動で入力し、
Enterキーを押します。 - このプロセスを数回繰り返すことで、Power Queryはより柔軟な変換ロジックを学習し、将来のデータ変動にも対応しやすくなります。
このステップが完了すると、Power QueryはバックグラウンドでM言語スクリプトを生成します。もし最初の推論が単純な区切り文字に依存していた場合でも、多様な例を与えることで、より複雑で汎用的なパターンを学習させることができます。もし推論がうまくいかない場合は、「適用したステップ」ペインの歯車アイコンから設定を調整するか、ステップを削除して最初からやり直すことも可能です。
実践!複雑な文字列からIDを抽出する方法
具体的なシナリオを通して、「例からの列」の強力なパターン認識能力を見ていきましょう。
シナリオ:変動する位置のID抽出
例えば、以下のようなログデータがあるとします。各文字列には5桁のIDが埋め込まれていますが、IDの前の月名(例: January, February)の長さによって、IDの開始位置が変動します。
Log-January-88392-DetailsLog-February-12345-DetailsLog-December-98765-Details
この場合、MID関数とFIND関数を組み合わせるのは非常に複雑になりますが、「例からの列」を使えば驚くほど簡単です。
- Power Queryエディターで「列の追加」タブの「例からの列」をクリックします。
- 新しい空の列の最初の行に、最初のログ文字列から抽出したいID(例:
88392)を入力し、Enterを押します。 - Power Queryが残りの行にIDの候補を表示します。もしすべての候補が正しければ「OK」をクリックします。
- もし誤った候補がある場合は、その行に正しいIDを手動で入力し、
Enterを押してPower Queryにさらに学習させます。
この操作だけで、Power Queryは文字列中の5桁の数字パターンを認識し、月名の長さに関わらず正確にIDを抽出するM言語スクリプトを生成します。数式を一切書くことなく、複雑なデータ抽出が実現できるのです。
実践!不揃いな氏名リストを標準化する方法
次に、複数の列を結合し、同時に書式を修正する例を見ていきましょう。
シナリオ:大文字・小文字が混在する氏名リストの標準化
「First Name」と「Last Name」の2つの列があり、それぞれ大文字・小文字が混在しているとします。さらに、「O’Connor」や「D’Angelo」のように、アポストロフィの後の文字も大文字にする必要がある特殊なケースも存在します。目標は、これらを結合して「Full Name」列を作成し、適切な大文字・小文字の書式に統一することです。
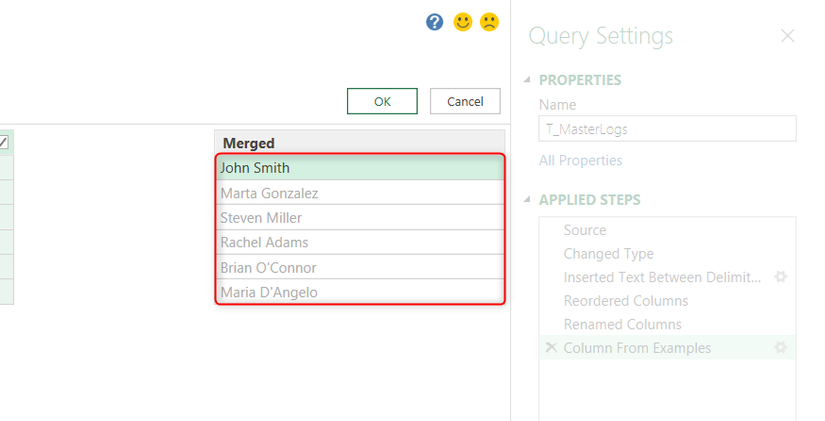
- Power Queryエディターで、
Ctrlキーを押しながら「First Name」列と「Last Name」列の両方を選択します。 - 「列の追加」タブの「例からの列」をクリックし、ドロップダウンメニューから「選択範囲から」を選択します。
- 新しい空の列の最初の行に、結合して整形したい氏名(例:
John Smith)を入力し、Enterを押します。 - Power Queryは、結合と適切な大文字・小文字の書式設定ロジックを推論し、残りの行に候補を表示します。驚くべきことに、「O’Connor」や「D’Angelo」のような特殊なケースでも、アポストロフィの後の文字を自動的に大文字にしてくれることが多いです。
- もし候補に間違いがあれば、そのセルをクリックして正しい氏名を入力し、Power Queryにさらに学習させます。
- すべての候補が正しければ「OK」をクリックして新しい列を追加します。
- 新しい「Full Name」列が追加されたら、元の「First Name」と「Last Name」列は不要になるため、右クリックして「削除」を選択します。Power Queryは変換ステップを記録しているため、中間列を削除しても最終的な出力には影響しません。
このように、「例からの列」は単なる抽出だけでなく、複数列の結合や複雑な書式設定も直感的な操作で実現できます。手作業では非常に手間がかかる作業も、数回の入力で自動化できるのです。
データ更新時の自動化:Power Queryの真価
「例からの列」の真の価値は、一度設定した変換が、元データの更新時に自動的に適用される点にあります。これはFlash Fillとの決定的な違いであり、データ処理のワークフローを劇的に改善します。
「閉じて読み込む」で結果を出力
Power Queryエディターで必要な変換がすべて完了したら、結果をExcelシートに出力します。
- 「ホーム」タブに移動します。
- 「閉じて読み込む」ボタンの上半分をクリックします。
- 整形されたデータが新しいExcelシートにテーブルとして読み込まれます。
元データ更新後の「更新」機能
ここからがPower Queryの「魔法」です。元のデータソース(この例ではT_MasterLogsテーブル)に新しい行を追加したり、既存のデータを変更したりしてみましょう。例えば、すべて小文字の氏名や、新しいID文字列を含む行を追加します。
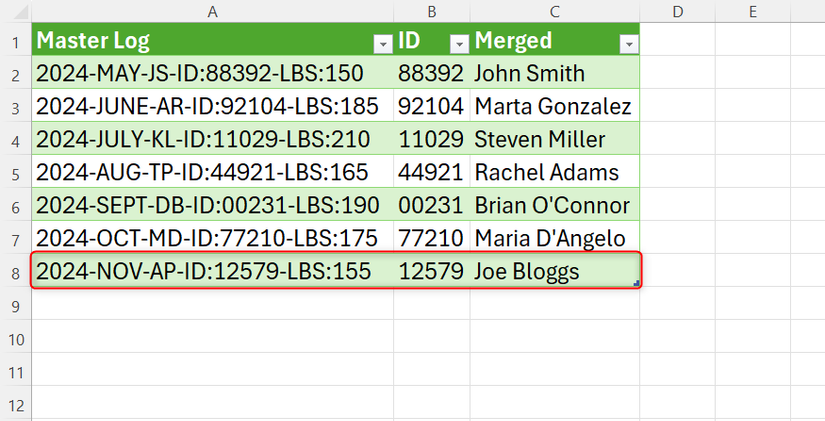
新しいデータが追加されたら、整形されたデータが出力されているシートに戻ります。テーブル内の任意の場所を右クリックし、「更新」をクリックしてください。すると、ExcelはPower QueryのM言語ロジックを自動的に実行し、追加された新しい行に対しても、IDの抽出や氏名の整形といった変換を瞬時に適用します。
この自動更新機能は、定期的に外部から取り込むデータや、常に変動するログデータなどを扱う際に絶大な威力を発揮します。一度クエリを設定すれば、以降は「更新」ボタンをクリックするだけで、常に最新かつ整形されたデータを得られるため、手作業によるデータ処理から解放されます。
もし、元データの構造が大幅に変わり、「更新」が失敗したとしても心配はいりません。Power Queryエディターに戻り、「適用したステップ」ペインで問題のステップを削除し、新しいパターンに合わせて「例からの列」を再トレーニングするだけで、簡単に修正できます。
「例からの列」はどんなユーザーにおすすめ?
Power Queryの「例からの列」機能は、特定のニーズを持つユーザーにとって特に価値のあるツールです。
- **データ入力ミスが多い部署の担当者:** 手入力によるデータの不統一や誤字脱字が多い場合、この機能を使えば、一貫したルールでデータを標準化し、品質を向上させることができます。
- **定期的に外部データを取り込む必要がある人:** 顧客リスト、販売データ、ログファイルなど、外部から取得するデータは形式が不揃いなことがよくあります。Power Queryを使えば、取り込みから整形までの一連のプロセスを自動化し、毎回の手作業をなくせます。
- **Excel作業の自動化・効率化を目指す人:** 複雑なVBAコードを書くスキルがなくても、直感的な操作で高度なデータ変換を自動化できるため、Excel作業の生産性を大幅に向上させたいと考えている人には最適です。
- **Flash Fillの限界を感じている人:** Flash Fillの便利さは認めつつも、データ更新時の手動再実行や、複雑なパターン認識の限界に不満を感じているユーザーは、「例からの列」の信頼性と自動化の恩恵を強く感じるでしょう。
- **データ分析の精度向上を目指す人:** 整形されたクリーンなデータは、その後のデータ分析の精度を大きく左右します。Power Queryは、分析の前段階でのデータ準備を効率的かつ正確に行うための強力な基盤を提供します。
データ品質向上と作業効率化への貢献
「例からの列」は、単にデータを整形するだけでなく、組織全体のデータ品質向上と作業効率化に大きく貢献します。手作業によるデータ処理は、時間とコストがかかるだけでなく、ヒューマンエラーのリスクも常に伴います。Power Queryを導入することで、これらのリスクを最小限に抑え、より信頼性の高いデータに基づいた意思決定を支援します。
また、データ整形にかかる時間を削減することで、従業員はより付加価値の高い分析や戦略立案に集中できるようになります。これは、個人の生産性向上だけでなく、組織全体の競争力強化にも繋がるでしょう。
Excelのデータ整形を効率化したいなら「例からの列」が最適解
ExcelのPower Queryに搭載されている「例からの列」機能は、複雑な数式やFlash Fillの限界を乗り越え、データ整形作業を劇的に効率化する強力なツールです。ユーザーがいくつかの例を示すだけで、Power Queryは高度なパターンを学習し、再利用可能で自動更新されるデータ変換ロジックを構築します。
文字列からのID抽出、不揃いな氏名リストの標準化、複数列の結合と書式設定など、多岐にわたるデータ整形タスクを直感的な操作で実現できるため、データクリーニングに費やす時間を大幅に削減し、データ品質の向上に貢献します。デスクトップ版Excelのフル機能が利用できないWeb版Excelユーザー向けには、「Formula by Example」という代替手段も用意されており、同様の恩恵を受けることが可能です。
一度「例からの列」の便利さを体験すれば、手動でのデータ整形や複雑な数式に戻ることは考えられなくなるでしょう。データ処理の自動化と効率化を目指すすべてのExcelユーザーにとって、この機能はまさに必携のスキルと言えます。
情報元:howtogeek.com