
データサイエンスや統計分析の分野では、従来の統合開発環境(IDE)やテキストエディタとは異なる、よりインタラクティブな開発スタイルが求められています。その中心にあるのが、IPythonとJupyter Notebookです。これらのツールは、単にコードを書くだけでなく、データを探索し、その場で結果を確認しながら思考を深める「探索的プログラミング」というアプローチを強力にサポートします。本記事では、IPythonとJupyter Notebookがデータサイエンティストのワークフローをどのように変革し、なぜ多くのプロフェッショナルに選ばれているのかを詳細に解説します。
探索的プログラミングとは?インタラクティブな開発の魅力
探索的プログラミングは、明確な最終目標を定めずに、試行錯誤を繰り返しながら問題解決のアプローチを見つけていく開発手法です。特にデータサイエンスの領域では、未知のデータセットを扱うことが多く、その内容や特性を事前に完全に把握することは困難です。このような状況において、IPythonやJupyter Notebookのようなインタラクティブなツールは、データセットを段階的に分析し、その場で結果を可視化することで、データの構造や潜在的なパターンを直感的に理解する手助けとなります。
従来のスクリプトベースの開発では、コードを記述し、実行し、結果を確認するというサイクルを繰り返す必要がありました。しかし、探索的プログラミングでは、コードの断片を即座に実行し、その結果をリアルタイムでフィードバックとして受け取ることができます。これにより、データサイエンティストは、より柔軟かつ効率的に仮説を立て、検証し、次のステップへと進むことが可能になります。このインタラクティブなアプローチこそが、データサイエンスにおけるIPythonとJupyter Notebookの最大の強みと言えるでしょう。
IPython:標準Pythonインタープリタを凌駕する機能
Pythonの標準インタープリタは、簡単なコードのテストや言語学習には役立ちますが、本格的なデータ探索にはいくつかの限界があります。例えば、タブ補完機能が限定的であったり、過去に実行したコードを効率的に再利用するのが難しいといった点が挙げられます。ここでその真価を発揮するのが、IPython(Interactive Python)です。
高度なタブ補完と履歴管理
IPythonの最も便利な機能の一つが、高度なタブ補完です。変数名、関数名、モジュール名などを入力中にTabキーを押すだけで、候補が自動的に表示され、入力の手間を大幅に削減できます。これは、現代のLinuxシェルが採用しているGNU Readlineライブラリと同様の仕組みで、開発効率を飛躍的に向上させます。また、コマンド履歴を簡単に遡ったり、検索したりする機能も充実しており、過去の試行錯誤を無駄にすることなく再利用できます。
「マジックコマンド」で分析を加速
IPythonには、通常のPythonコードとは異なる「マジックコマンド」と呼ばれる特殊なコマンドが組み込まれています。これらはパーセント記号(%)で始まり、システムの操作やコードのプロファイリングなど、様々な便利な機能を提供します。例えば、%timeitコマンドは、特定のコードブロックの実行時間を正確に計測するのに役立ちます。
以下に、NumPyを使って行列の最小二乗解を計算し、その実行時間を計測する例を示します。

この例では、小さな行列(10×3)の場合、約12マイクロ秒で計算が完了しました。行列のサイズを大きくして(500×3)再度計測すると、約22マイクロ秒という結果が得られます。このように、%timeitはアルゴリズムのパフォーマンス比較や最適化の際に非常に強力なツールとなります。
Jupyter Notebook:コード、テキスト、グラフィックを融合
IPythonが強力なインタラクティブシェルであるのに対し、Jupyter Notebookはそれをさらに発展させ、コード、テキスト、グラフィックを一つのドキュメントに統合できるインタラクティブな「ノートブック」環境を提供します。これは、伝説的なコンピューター科学者ドナルド・クヌースが提唱した「リテラシープログラミング」の概念を具現化したもので、プログラムのコードだけでなく、その背景にある思考プロセスや分析結果を、人間が理解しやすい形で記述・共有することを可能にします。
セル構造と多様なコンテンツ
Jupyter Notebookは「セル」と呼ばれる単位で構成されており、各セルにはPythonなどのコード、またはMarkdown形式のテキストを記述できます。これにより、コードの実行結果(数値、グラフ、表など)をそのコードのすぐ下に表示できるため、分析の流れを非常に分かりやすく追うことができます。また、Markdownセルを活用することで、分析の目的、使用した手法、得られた洞察などを詳細に記述し、ドキュメントとしての完成度を高めることが可能です。
多言語対応と永続性
Jupyterは元々IPythonから派生しましたが、現在ではPythonだけでなく、R、Julia、Scalaなど、様々なプログラミング言語(カーネル)をサポートしています。これにより、データサイエンスの多様なニーズに対応できる汎用性の高いツールとなっています。
Jupyter Notebookの最大の特長の一つは、その「永続性」です。一度作成したノートブックは、コード、実行結果、テキスト、グラフなど、すべての情報を保存できます。これにより、数日後、数週間後に同じ分析を再開する際にも、以前の作業内容を正確に再現し、どこからでも作業を継続できます。また、ノートブックファイルを共有することで、他の研究者や同僚と分析結果や思考プロセスを容易に共有し、共同作業を円滑に進めることが可能です。
IPythonとJupyter Notebookの使い分け:探索と永続性
IPythonとJupyter Notebookはどちらもインタラクティブな開発をサポートしますが、その特性から使い分けが可能です。
- IPython: 短時間の実験や使い捨ての計算に最適です。例えば、特定の関数の動作を素早く確認したい場合や、複雑な数式の結果を一時的に計算したい場合など、すぐに結果が欲しい状況で活躍します。バックグラウンドで常に起動させておき、究極の「デスク電卓」として活用することもできます。
- Jupyter Notebook: データ探索、詳細な分析、結果の共有、長期的なプロジェクトに適しています。分析の過程を記録し、後から見返したり、他者と共有したりする必要がある場合にその真価を発揮します。例えば、データセットの特性を深く掘り下げ、複数の可視化手法を試しながら洞察を得るような作業には、Jupyter Notebookの永続性と表現力が不可欠です。
データサイエンティストは、これらのツールを状況に応じて使い分けることで、効率的かつ効果的なデータ分析ワークフローを構築できます。例えば、Pixiのような環境管理ツールと組み合わせることで、必要なライブラリを簡単にセットアップし、再現性の高い分析環境を構築することも可能です。
実践!Jupyter Notebookでデータ分析ワークフローを体験
Jupyter Notebookがデータ分析においてどのように活用されるのか、具体的なワークフローを通じて見ていきましょう。ここでは、レストランのチップに関するデータセットを例に、データの読み込み、概要統計の確認、可視化、そして簡単な回帰分析までの一連の流れを追体験します。
環境の準備とデータの読み込み
まず、Jupyter Notebookを起動し、必要なライブラリをインポートします。データ分析には、数値計算のNumPy、データ操作のpandas、統計的グラフィックのSeaborn、統計モデリングのSciPyとstatsmodelsがよく用いられます。また、グラフをノートブック内に直接表示させるために%matplotlib inlineマジックコマンドを使用します。
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_theme()
from scipy import stats
import statsmodels.api as sm
import statsmodels.formula.api as smf
%matplotlib inline次に、Seabornに内蔵されている「tips」データセットを読み込み、pandasのDataFrameとして格納します。
tips = sns.load_dataset('tips')データの概要把握
データセットの先頭部分を確認することで、どのようなデータが含まれているかを把握します。
tips.head()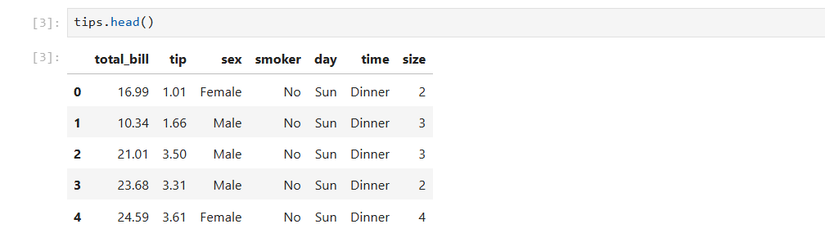
さらに、数値列の記述統計量(平均、標準偏差、最小値、四分位数、最大値など)を確認し、データの分布や特性をより深く理解します。
tips.describe()データの可視化と関係性の探索
データサイエンスにおいて、可視化はデータのパターンや異常値を特定する上で不可欠です。ここでは、請求額(total_bill)とチップ(tip)の分布をヒストグラムで確認し、両者の関係を散布図で見てみましょう。
sns.displot(x='total_bill',data=tips)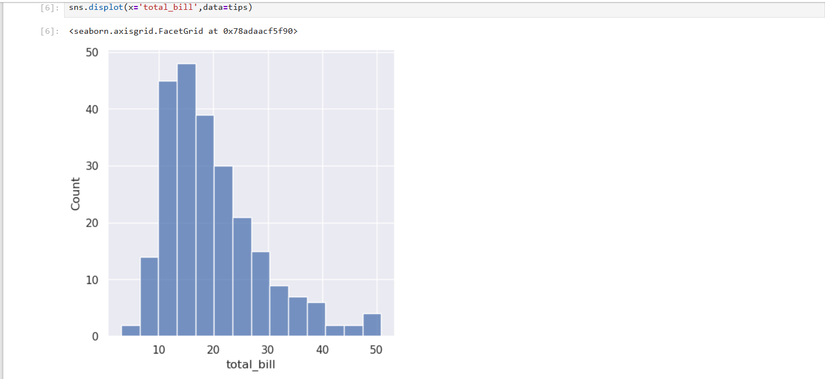
sns.displot(x='tip',data=tips)請求額とチップの散布図を作成し、回帰直線を追加することで、両者の間にどのような線形関係があるかを視覚的に捉えることができます。
sns.relplot(x='total_bill',y='tip',data=tips)
sns.regplot(x='total_bill',y='tip',data=tips)散布図と回帰直線から、請求額が増えるにつれてチップも増えるという正の線形関係が示唆されます。
統計モデリングによる関係性の定量化
この関係性をさらに定量的に評価するために、statsmodelsライブラリを用いて線形回帰モデルを構築します。R言語で普及した数式表記法を使用し、チップを目的変数、請求額を説明変数としてモデルを適合させます。
results = smf.ols('tip ~ total_bill',data=tips).fit()
results.summary()モデルのサマリー結果からは、y切片と傾き(この場合はtotal_billの係数)の値が示され、y = mx + bという形式でチップと請求額の関係を数学的に表現できます。このように、Jupyter Notebookは、データの探索から可視化、統計モデリングまでの一連のデータ分析ワークフローを、一つのインタラクティブな環境で完結させることを可能にします。
データサイエンスにおけるIPythonとJupyterの未来
IPythonとJupyter Notebookは、データサイエンスの分野において、単なるツールを超えた存在となっています。これらは、データサイエンティストがデータを「語り」、その物語を共有するための強力なプラットフォームを提供します。探索的プログラミングというアプローチは、データから新たな知見を引き出し、複雑な問題を解決するための思考プロセスを柔軟かつ効率的にサポートします。
これらのツールは、教育現場から研究機関、そして企業のデータ分析部門に至るまで、幅広い分野で標準的な開発環境として採用されています。今後も、より高度なインタラクティブ機能、クラウド連携の強化、そしてAI/機械学習モデルの開発・デプロイメントへの統合が進むことで、データ駆動型社会におけるその重要性はさらに増していくことでしょう。データサイエンスの進化とともに、IPythonとJupyter Notebookもまた、その可能性を広げ続けています。
こんな人におすすめ!IPythonとJupyter Notebookの活用
IPythonとJupyter Notebookは、以下のような方々に特におすすめできるツールです。
- データサイエンスの学習者: コードの実行結果をすぐに確認できるため、Pythonやデータ分析ライブラリの学習効率が格段に向上します。
- 研究者・アナリスト: 複雑なデータ分析の過程を詳細に記録し、結果を分かりやすく共有したい場合に最適です。論文の補足資料や共同研究での情報共有に役立ちます。
- データエンジニア・開発者: データの前処理や探索的データ分析(EDA)を効率的に行いたい場合、また、プロトタイピングやアルゴリズムの検証にインタラクティブな環境を求める場合に有効です。
- 統計学を学ぶ学生: 統計モデルの構築や仮説検定のプロセスを、コードと解説、結果を一体化させて学ぶことができます。
これらのツールを使いこなすことで、データ分析の生産性と再現性を高め、より深い洞察を得ることが可能になります。
情報元:howtogeek.com