
データサイエンスの現場では、従来の統合開発環境(IDE)やテキストエディタとは異なるアプローチが求められることがあります。特に、未知のデータセットを扱う探索的な分析においては、IPythonとJupyter Notebookがその真価を発揮し、多くのデータサイエンティストにとって不可欠なツールとなっています。これらのツールは、単なるコード実行環境に留まらず、データとの対話を可能にし、分析プロセスを劇的に効率化します。本記事では、IPythonとJupyter Notebookがなぜデータサイエンスのワークフローにおいて強力な選択肢となるのか、その機能と具体的な活用法を深掘りしていきます。
探索的プログラミングとは?データ分析におけるその価値
従来のプログラミングは、明確な目標を設定し、それに従ってコードを記述し、実行するという線形的なワークフローが一般的でした。しかし、データサイエンスや統計学の分野では、データセットの内容が事前に完全に把握されていることは稀です。ここで重要となるのが「探索的プログラミング」という概念です。
探索的プログラミングとは、明確な最終目標を持たずに、試行錯誤を繰り返しながらデータセットを深く理解していくアプローチを指します。コードを書き、即座に結果を確認し、その結果に基づいて次のステップを決定するという、対話的かつ反復的なプロセスが特徴です。これにより、データに潜むパターンや異常値、相関関係などを効率的に発見し、より深い洞察を得ることが可能になります。
従来のIDEやスクリプト実行では、コードの変更ごとに全体を再実行する必要があり、この探索的なプロセスには不向きでした。しかし、IPythonやJupyter Notebookのようなツールは、この探索的プログラミングを強力にサポートするために設計されており、データサイエンティストがデータと「会話」しながら分析を進めることを可能にします。
IPythonの進化:インタラクティブなPython環境の真価
Pythonの標準インタプリタは、簡単なコードのテストや言語学習には便利ですが、本格的なデータ分析にはいくつかの限界があります。例えば、タブ補完機能が限定的であったり、過去に実行したコードを効率的に再利用するのが難しいといった点です。
IPython(Interactive Python)は、これらの標準インタプリタの課題を解決するために開発されました。IPythonは、より高度なインタラクティブシェルを提供し、データサイエンティストの生産性を大幅に向上させます。
強化された機能でPython開発を効率化
- 強力なタブ補完: 変数名、関数名、モジュール名などを入力中にTabキーを押すだけで、候補が自動的に表示・補完されます。これにより、タイピングミスを減らし、開発速度を向上させます。
- コマンド履歴の管理: 過去に実行したコマンドを簡単に呼び出し、編集、再実行できます。これは、LinuxシェルでGNU Readlineライブラリが提供する機能と同様で、試行錯誤の多いデータ分析において非常に役立ちます。
- 「マジックコマンド」の導入: IPythonには、パーセント記号(%)で始まる特殊なコマンド、通称「マジックコマンド」が組み込まれています。これらは、Pythonコードの実行を補助する様々な機能を提供します。例えば、
%timeitコマンドは、特定のコードブロックの実行時間を正確に計測するのに使用できます。
例えば、NumPyで生成した行列の最小二乗解を計算する際の実行時間を計測する場合、以下のように%timeitを使用します。
import numpy as np
rng = np.random.default_rng()
X = rng.random((10,3))
y = rng.random(10)
%timeit np.linalg.lstsq(X,y)このコマンドを実行すると、コードの実行にかかった時間がマイクロ秒単位で表示され、パフォーマンスのボトルネックを特定するのに役立ちます。小さな行列では数マイクロ秒、より大きな行列でも数十マイクロ秒といった高速な結果が得られることが示されています。

Jupyter Notebookの真髄:コード、テキスト、可視化の融合でデータ分析を加速
IPythonが強力なインタラクティブシェルであるのに対し、Jupyter Notebookはそれをさらに発展させ、データ分析のワークフロー全体を革新するツールです。Jupyter Notebookは、コード、実行結果、説明テキスト(Markdown形式)、そしてグラフや画像といったメディアを一つのドキュメントに統合できる「インタラクティブなノートブック」環境を提供します。
「リテラシープログラミング」の具現化
Jupyter Notebookの根底には、伝説的なコンピュータ科学者ドナルド・クヌースが提唱した「リテラシープログラミング」の思想があります。これは、単にコンピュータが実行できるコードを書くだけでなく、人間が理解しやすいようにコードと説明文を組み合わせ、プログラムの意図や動作原理を明確に記述するというアプローチです。Jupyter Notebookは、この思想を具現化し、データ分析のプロセスを透明化し、再現性を高めます。
Jupyter Notebookの主要な特徴
- セルベースの構造: ノートブックは「セル」と呼ばれるブロックで構成され、各セルにはコード、Markdown形式のテキスト、または生データを含めることができます。コードセルを実行すると、その結果が直下に表示され、グラフもインラインで描画されます。
- 多言語対応: 元々はIPythonから派生しましたが、JupyterはPythonだけでなく、R、Julia、Scalaなど、様々なプログラミング言語(カーネル)をサポートしています。これにより、異なる言語を使用するデータサイエンティストが同じ環境で作業できます。
- 永続性と共有: Jupyter Notebookは、分析の過程と結果を
.ipynbファイルとして保存できます。これにより、後から自分の作業を振り返ったり、他の研究者や同僚と分析結果やコードを簡単に共有したりすることが可能です。これは、データ探索の再現性を確保し、共同作業を円滑に進める上で極めて重要な機能です。
実践!Jupyter Notebookでデータ分析ワークフローを体験
Jupyter Notebookの真価は、実際のデータ分析ワークフローで発揮されます。ここでは、典型的な統計分析の例を通じて、その強力な機能を体験してみましょう。今回は、ウェイターが記録したチップに関するデータセットを使用します。
必要なライブラリのインポートとデータ準備
まず、データ分析に必要なライブラリをインポートします。NumPy(数値計算)、pandas(データ操作)、Seaborn(データ可視化)、SciPy(科学計算)、statsmodels(統計モデリング)などが一般的です。また、Matplotlibのプロットをノートブック内に直接表示させるための設定も行います。
import numpy as np
import pandas as pd
import seaborn as sns
sns.set_theme()
from scipy import stats
import statsmodels.api as sm
import statsmodels.formula.api as smf
%matplotlib inline次に、Seabornに内蔵されている「tips」データセットを読み込み、pandasのDataFrameとして扱います。
tips = sns.load_dataset('tips')データの探索と記述統計
データセットの最初の数行を確認し、どのようなデータが含まれているかを把握します。
tips.head()その後、数値列の記述統計量(平均、標準偏差、最小値、四分位数、最大値など)を計算し、データの全体像を掴みます。
tips.describe()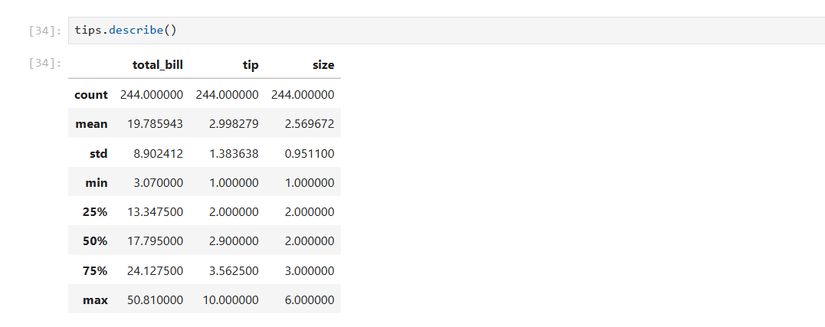
データの可視化による洞察
データセットの分布を視覚的に確認することは、探索的データ分析において非常に重要です。例えば、総支払い額(total_bill)とチップ(tip)の分布をヒストグラムで表示します。
sns.displot(x='total_bill',data=tips)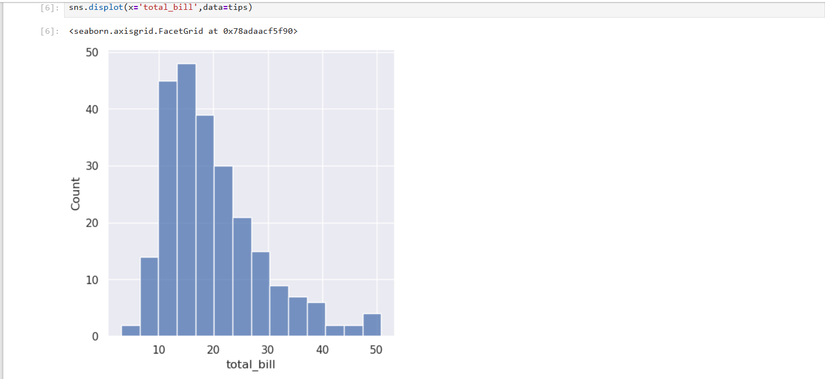
sns.displot(x='tip',data=tips)さらに、総支払い額とチップの関係を散布図で可視化し、回帰直線を追加することで、両者の間にどのような線形関係があるかを視覚的に確認できます。
sns.relplot(x='total_bill',y='tip',data=tips)
sns.regplot(x='total_bill',y='tip',data=tips)散布図に回帰直線を追加すると、総支払い額が増えるにつれてチップも増加する、正の線形関係があることが示唆されます。
統計モデリングによる関係性の定量化
視覚的な確認だけでなく、統計モデルを用いてこの関係性を定量的に評価します。ここでは、最小二乗法(OLS)を用いて、チップが総支払い額によってどのように説明されるかをモデル化します。
results = smf.ols('tip ~ total_bill',data=tips).fit()
results.summary()この結果から、y切片と傾き(この場合はtotal_billの係数)の値が得られ、y = mx + bという形式の回帰方程式を構築できます。これにより、総支払い額がチップに与える影響を具体的な数値で把握することが可能になります。
このように、Jupyter Notebookでは、データの読み込みから前処理、探索、可視化、そして統計モデリングまでの一連のデータ分析ワークフローを、一つのドキュメント内でシームレスに実行し、記録することができます。これは、まさに「ボトムアップ型プログラミング」の典型であり、探索を通じて完全な分析を構築し、その結果を他者と共有するのに最適な環境です。
IPythonとJupyter、どちらを選ぶべきか?最適なデータ分析ツール選び
IPythonとJupyter Notebookは、どちらもデータサイエンスにおいて強力なツールですが、その用途には明確な違いがあります。状況に応じて適切なツールを選択することが、効率的なワークフローを構築する鍵となります。
IPythonが最適なケース
- クイックな実験や計算: 複雑なスクリプトを書くほどではないが、Pythonの機能を活用して素早く計算結果を確認したい場合。例えば、数学的な式の評価、ライブラリの特定の関数の動作確認など。
- 使い捨ての計算: 後で参照する必要のない一時的なデータ操作や、ちょっとしたコードスニペットのテスト。
- バックグラウンドでの実行: ターミナルでIPythonセッションを起動し、必要に応じて呼び出して使用するような、常駐型の「究極のデスク計算機」として活用したい場合。
IPythonは、その即応性と軽量性から、データ分析の初期段階でのアイデア検証や、日々のちょっとした計算に非常に適しています。
Jupyter Notebookが最適なケース
- 永続的なデータ探索と分析: データセットを深く掘り下げ、その過程と結果を詳細に記録したい場合。分析の再現性を確保し、後から自分の思考プロセスを追跡できるようにしたい場合に最適です。
- 結果の共有とプレゼンテーション: 分析結果を他のチームメンバー、研究者、または非技術的な関係者と共有する必要がある場合。コード、説明、グラフが一体となったノートブックは、非常に分かりやすいドキュメントとなります。
- 教育や学習: プログラミングやデータサイエンスの概念を教えたり学んだりする際に、ステップバイステップでコードと解説を提示できるため、非常に効果的な教材となります。
- 複雑なデータ可視化: MatplotlibやSeabornなどのライブラリを使って、多様なグラフやチャートを生成し、それらをテキストの説明とともに整理して表示したい場合。
Jupyter Notebookは、その包括的な機能とドキュメント化能力により、本格的なデータ分析プロジェクトや共同作業において、その真価を発揮します。
こんな人におすすめ
データサイエンスの学習を始めたばかりの初心者から、日々の業務で大量のデータを扱うベテランまで、IPythonとJupyter Notebookは幅広いユーザーに推奨されます。特に、データから新しい知見を引き出すための「探索的データ分析(EDA)」を効率的に行いたい方、分析プロセスを透明化し、再現性のある形で共有したい方には、これらのツールが強力な味方となるでしょう。従来のIDEでは得られない、データとの対話的な体験を通じて、より深い洞察と効率的なワークフローを実現したいすべての人に、IPythonとJupyter Notebookの導入を強くお勧めします。
まとめ:データサイエンスの未来を拓くツール
IPythonとJupyter Notebookは、単なるプログラミングツールではなく、データサイエンスのワークフローそのものを変革する可能性を秘めています。IPythonの強化されたインタラクティブシェルは、Pythonでのクイックな実験や計算を効率化し、Jupyter Notebookはコード、テキスト、可視化を統合することで、探索的データ分析のプロセスを劇的に改善します。
これらのツールが提供する「探索的プログラミング」のアプローチは、未知のデータセットから新たな洞察を引き出し、分析結果の透明性と再現性を高める上で不可欠です。データサイエンティストは、これらのツールを使いこなすことで、より迅速に、より深くデータと対話し、ビジネスや研究における意思決定に貢献できるでしょう。データ駆動型社会が加速する現代において、IPythonとJupyter Notebookは、データサイエンスの未来を拓くための重要な基盤となることは間違いありません。
情報元:howtogeek.com